【JavaScript】正则表达式语法
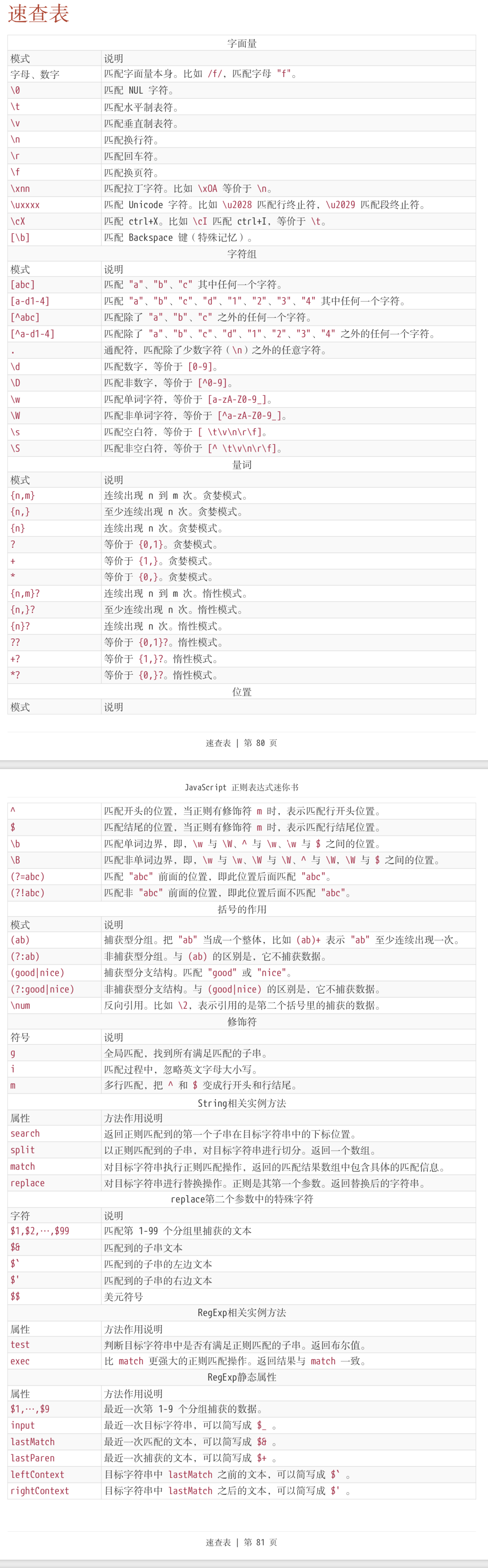
正则语法速查表
正则表达式中的特殊字符
断言
表示一个匹配在某些条件下发生。断言包含先行断言、后行断言和条件表达式。
^
匹配输入的开头。如果多行模式设为 true,^ 在换行符后也能立即匹配,比如 /^A/ 匹配不了 "an A" 里面的 "A",但是可以匹配 "An A" 里面第一个 "A"。
注意与
[^xyz]的区别。$
匹配输入的结束。如果多行模式设为 true,^ 在换行符前也能立即匹配,比如 /t$/ 不能匹配 "eater" 中的 "t",但是可以匹配 "eat" 中的 "t"。
\b
匹配一个单词的边界,这是一个字的字符前后没有另一个字的字符位置, 例如在字母和空格之间。需要注意的是匹配的单词边界不包括在匹配中。换句话说,匹配字边界的长度为零。
- /\bm/ 在 "moon" 中匹配到 "m"。
- /oo\b/ 在 "moon" 中不会匹配到 "oo", 因为 "oo" 后面跟着 "n" 这个单词字符。
- /oon\b/ 在 "moon" 中匹配 "oon", 因为 "oon" 是这个字符串的结尾, 因此后面没有单词字符。
- /\w\b\w/ 将永远不会匹配任何东西,因为一个单词字符后面永远不会有非单词字符和单词字符。
注意与
[\b]的区别\B
匹配非单词边界,这是上一个字符和下一个字符属于同一类型的位置:要么两者都必须是单词,要么两者都必须是非单词。
x(?=y)
向前断言,x 后紧随 y 时匹配 x,匹配结果不包括 y。
x(?!y)
向前否定断言,x 后没有紧随 y 时匹配 x,匹配结果不包括 y。
(?<=y)x
向后断言,x 紧随 y 时匹配 x,匹配结果不包括 y。
(?<!y)x
向后否定断言,x 不紧随 y 时匹配 x,匹配结果不包括 y。
字符
区分不同类型的字符,例如区分字母和数字。
.
匹配除行终止符之外的任何单个字符,
/.y/在"yes make my day"中匹配的是my和ay,换成/..y/匹配的则是my(注意空格) 和day\d & \D
\d 匹配数字,相当于
[0-9]。\D 匹配非数,相当于
[^0-9]。\w & \W
\w 匹配字符,包括下划线,相当于
[A-Za-z0-9_]\W 匹配非字符,相当于
[^A-Za-z0-9_]\s & \S
\s 匹配一个空白字符,包括空格、制表符、换行符和其他 Unicode 空格,相当于
[ \f\n\r\t\v\u00a0\u1680\u2000-\u200a\u2028\u2029\u202f\u205f\u3000\ufeff]\S 匹配非空白字符
[^ \f\n\r\t\v\u00a0\u1680\u2000-\u200a\u2028\u2029\u202f\u205f\u3000\ufeff]其他字符 \t 匹配水平制表符(tab) \r 匹配回车 \n 匹配换行 \v 匹配垂直制表符 \f 匹配分页符 [\b] 匹配退格,注意与断言类 \b 的区别 \0 匹配 Null Character(空字符),后不能跟数字,在 js 中未找到匹配该规则的字符串 \xhh 匹配编码 hh(两个十六进制数字)的字符。 \uhhhh 用值 hhhh(4 个十六进制数字)匹配 UTF-16 编码。
组和范围
x | y
匹配 x 或 y 。
[xyz][a-c]
匹配任何包含的字符。可以使用连字符来指定字符范围,但如果连字符是方括号的第一个或最后一个字符,则它将被作为普通字符包含在字符集中的文字连字符。
例如,
[abcd]与[a-d]是一样的,[-abcd]会匹配non-profit中的-。[^xyz] [^z-c]
匹配任何没有包含在括号中的字符。
(x)
捕获组,匹配 x 并记住匹配项。
正则表达式可以有多个捕获组,捕获组的顺序是正则中左括号的顺序。
括号并不会影响其他规则,如:
/[abc]/和/[a(b)c]/都可以匹配 字符串中的a、b、c,区别在于使用了括号后可以通过\n来引用捕获组中的内容。\n
引用第 n 个捕获组的内容,使用形式为 \1、\2,表示引用第一个、第二个捕获组匹配的内容。序号从 0 开始,注意 \0 是另外的正则语法。
注意与字符类 \n 的区别。
(?<Name>x)具名捕获组,匹配"x"并将其存储在返回的匹配项的 groups 属性中,
'web-doc'.match(/-(?<customName>\w)/).groups //{customName: "d"}(?:x)
非捕获组,匹配 x 但是不记录在捕获组中,即无法用 \n 引用也不记录在捕获组对象的 groups 中。适用于有多个捕获组时忽略掉一些捕获组以更好的使用 \n 的情况,js 中的正则有具名捕获组的概念,所以这个语法只能限制 \n 的使用?
量词
x*
将前面的项 x 匹配 0 次或多次。
x +
将前面的项 x 匹配 1 次或多次,等价于 {1,}(见下文)。
x?
将前面的项 x 匹配 0 或 1 次。
注意在量词(包括自己,也就是可以有 x?? 这样的用法)后使用时的含义变化(非贪婪匹配)。
x
将前面的项 x 匹配 n 次,n 为整数。
x
将前面的项 x 匹配至少 n 次。
x
将前面的项匹配 [n,m] 次
量词的贪婪匹配与非贪婪匹配
量词默认情况下是贪婪匹配,如果在任何量词*、+、?或{}之后使用?,则使量词进行非贪婪匹配。
贪婪匹配:匹配尽可能多的字符串。 非贪婪匹配:一旦找到匹配对象就立即停止。
如:'aaaaaaaaaaaa'.match(/a{2,5}/g); // ["aaaaa", "aaaaa", "aa"],使用非贪婪匹配后则是:'aaaaaaaaaaaa'.match(/a{2,5}?/g); // ["aa", "aa", "aa", "aa", "aa", "aa"]
Unicode 属性转义
使用 Unicode 属性可以匹配表情、标点符号、字母(甚至适用特定语言或文字)等。
正则表达式标志
| 标志 | 描述 |
|---|---|
g | 全局搜索。 |
i | 不区分大小写搜索。 |
m | 多行搜索。 |
s | 允许 . 匹配换行符。 |
u | 使用 unicode 码的模式进行匹配。 |
y | 执行“粘性(sticky)”搜索,匹配从目标字符串的当前位置开始。 |
使用正则表达式
如果只是为了判断是否匹配(true 或 false),可以使用 RegExp.test() 或者 String.search() 方法。
如果想获取所有匹配项可以用 String.match() 方法,注意要添加全局标志(g)。
如果想查看每次匹配的详情可以用 RegExp.exec() 方法(注意全局标志的影响),可以通过捕获组的 index 和每次调用后的 RegExp.lastIndex 可以确定这次匹配的开始和结束位置。
如果想获取所有匹配项的捕获组可以用 String.matchAll() 方法,注意要添加全局标志(g)。无法监控 RegExp.lastIndex 的状态。
RegExp.prototype.exec(str)
使用全局标志:字符串中有匹配项时返回这条匹配信息的捕获组,同时更新 RegExp.lastIndex 属性;不匹配不匹配时返回 null,同时 RegExp.lastIndex 属性设置为 0。
不使用全局标志:返回第一个匹配项的捕获组或 null。
如果要获得所有匹配的捕获组可以使用 String.prototype.matchAll(reg) 方法。
通过捕获组的 index 和每次调用后的 RegExp.lastIndex 可以确定这次匹配的开始和结束位置。
var str = "我今年25岁明年26岁后年27岁千年24岁";
var reg1 = /\d+/g;
var reg2 = /\d+/;
// 使用global或sticky标志在下次调用exec时会从上一次匹配位置(lastIndex)之后进行匹配
reg1.exec(str); // ["25", index: 3, input: "我今年25岁明年26岁后年27岁千年24岁", groups: undefined]
reg1.exec(str); // ["26", index: 8, input: "我今年25岁明年26岁后年27岁千年24岁", groups: undefined]
reg1.exec(str); // ["27", index: 13, input: "我今年25岁明年26岁后年27岁千年24岁", groups: undefined]
reg1.exec(str); // ["25", index: 3, input: "我今年25岁明年26岁后年27岁千年24岁", groups: undefined]
reg1.exec(str); // null
// 没有使用global或sticky标志则不会记录状态
reg2.exec(str); // ["25", index: 3, input: "我今年25岁明年26岁后年27岁千年24岁", groups: undefined]
reg2.exec(str); // ["25", index: 3, input: "我今年25岁明年26岁后年27岁千年24岁", groups: undefined]
注意,即使再次查找的字符串不是原查找字符串时,lastIndex 也不会被重置,它依旧会从记录的 lastIndex 开始。
let str1 = "我今年25岁明年26岁后年27岁千年24岁";
let str2 = "我今年25岁明年26岁后年27岁千年24岁";
let reg = /\d+/g;
reg.exec(str1); // ["25", index: 3, input: "我今年25岁明年26岁后年27岁千年24岁", groups: undefined]
reg.lastIndex; // 5
reg.exec(str1); // ["26", index: 8, input: "我今年25岁明年26岁后年27岁千年24岁", groups: undefined]
reg.lastIndex; // 10
reg.exec(str2); // ["27", index: 13, input: "我今年25岁明年26岁后年27岁千年24岁", groups: undefined]
reg.lastIndex; // 15
reg.exec(str2); // ["25", index: 3, input: "我今年25岁明年26岁后年27岁千年24岁", groups: undefined]
reg.lastIndex; // 20
reg.exec(str1); // null
reg.lastIndex; // 0
匹配成功后更新 lastIndex 属性,匹配失败时将 lastIndex 重置为 0。
RegExp.prototype.test(str)
查看正则表达式与指定的字符串是否匹配,返回 true 或 false。
类似于 String.prototype.search() 方法,差别在于 test 返回一个布尔值,而 search 返回索引(如果找到)或者-1(如果没找到)。
如果正则表达式设置了全局标志,test() 的执行会改变正则表达式 lastIndex 属性。连续的执行 test()方法,后续的执行将会从 lastIndex 处开始匹配字符串。
同 exec 一样,匹配成功后更新 lastIndex 属性,匹配失败时将 lastIndex 重置为 0。
var str = "我今年25岁明年26";
var reg1 = /\d+/g;
var reg2 = /\d+/;
// 使用global或sticky标志在下次调用test时会从上一次匹配位置(lastIndex)之后进行匹配
reg1.test(str); // true
reg1.test(str); // true
reg1.test(str); // false
// 没有使用global或sticky标志则不会记录状态
reg1.test(str); // true
reg1.test(str); // true
reg1.test(str); // true
String.prototype.match(reg)
如果使用全局标志,则返回与正则表达式匹配的所有结果的数组。
如果未使用全局标志,则仅返回第一个完整匹配及其相关的捕获组(Array),其返回值与不带全局标志的 reg.exec() 的返回值相同。
var str = "我今年25岁明年26岁后年27岁千年24岁";
var reg1 = /\d+/g;
var reg2 = /\d+/;
// 使用全局标志则返回所有匹配项
str.match(reg1); // ["25", "26", "27", "24"]
// 没有全局标志返回第一个匹配项的[捕获组](编程基础\WebAPI\ECMAScript\对象\RegExp.md#捕获组),不会修改lastIndex属性
str.match(reg2); // ["25", index: 3, input: "我今年25岁明年26岁后年27岁千年24岁", groups: undefined]
str.match(reg2); // ["25", index: 3, input: "我今年25岁明年26岁后年27岁千年24岁", groups: undefined]
String.prototype.matchAll(reg)
返回匹配捕获组的迭代器,这里的正则必须带全局标志,否则会报错。
这里的返回结果与依次调用 RegExp.exec() 方法得到的结果一致。
使用 matchAll 方法无法监控 RegExp.lastIndex 的变化。
var str = "我今年25岁明年26岁后年27岁千年24岁";
var reg1 = /\d+/g;
var arr = [...str.matchAll(reg1)];
// [
// ["25", index: 3, input: "我今年25岁明年26岁后年27岁千年24岁", groups: undefined]
// ["26", index: 8, input: "我今年25岁明年26岁后年27岁千年24岁", groups: undefined]
// ["27", index: 13, input: "我今年25岁明年26岁后年27岁千年24岁", groups: undefined]
// ["24", index: 18, input: "我今年25岁明年26岁后年27岁千年24岁", groups: undefined]
// ]
String.prototype.search(reg)
返回正则表达式在字符串中首次匹配项的索引;无匹配则返回 -1。全局标志对此方法无影响。
var str = "我今年25岁明年26";
var reg1 = /\d+/g;
var reg2 = /\d+/;
// 全局标志对结果无影响
str.search(reg1); // 3
str.search(reg1); // 3
String.prototype.replace(regexp|substr, newSubStr|function)
特殊变量名
二参为字符串时可设置以下特殊字符串
| 变量名 | 代表的值 |
|---|---|
| $$ | 插入一个 "$"。 |
| $&` | 插入匹配的子串。 |
| $` | 插入当前匹配的子串左边的内容。 |
| $' | 插入当前匹配的子串右边的内容。 |
| $n | 假如第一个参数是 RegExp 对象,并且 n 是个小于 100 的非负整数,那么插入第 n 个括号匹配的字符串。提示:索引是从 1 开始。如果不存在第 n 个分组,那么将会把匹配到到内容替换为字面量。比如不存在第 3 个分组,就会用“$3”替换匹配到的内容。 |
$<Name> | 这里 `Name 是一个分组名称。如果在正则表达式中并不存在分组(或者没有匹配),这个变量将被处理为空字符串。只有在支持命名分组捕获的浏览器中才能使用。 |
指定函数作为参数
二参为函数时接收以下参数
| 变量名 | 代表的值 |
|---|---|
match | 匹配的子串。 |
p1,p2, ... | 假如 replace()方法的第一个参数是一个 RegExp 对象,则代表第 n 个括号匹配的字符串。(对应于上述的$1,$2 等。)例如,如果是用 /(\a+)(\b+)/ 这个来匹配,p1 就是匹配的 \a+,p2 就是匹配的 \b+。 |
offset | 匹配到的子字符串在原字符串中的偏移量,也就是索引。(比如,如果原字符串是 'abcd',匹配到的子字符串是 'bc',那么这个参数将会是 1) |
string | 被匹配的原字符串。 |
| NamedCaptureGroup | 命名捕获组匹配的对象 |
String.prototype.split(regexp|substr, limit?)
分隔字符串,二参为限定分隔的次数。
其他概念
RegExp.lastIndex
lastIndex 是正则表达式的一个可读可写的整型属性,用来指定下一次匹配的起始索引。
lastIndex 表示上次成功匹配的最后位置。
会修改 reg.lastIndex 属性(设置全局标志)的 API 包括:RegExp.exec()、RegExp.test()。
捕获组
一个捕获组的数据格式为:["25", index: 3, input: "我今年25岁明年26岁后年27岁千年24岁", groups: undefined]
在设置了 global 或 sticky 标志位的情况下(如 /foo/g or /foo/y),JavaScript RegExp 对象是有状态的。他们会将上次成功匹配后的位置记录在 lastIndex 属性(当前 RegExp 表达式的属性,即 reg.lastIndex)中。
- 前面的字符串表示匹配的字符串和捕获组匹配的字符串
- index: 匹配的结果的开始位置。
- input: 完整字符串。
- groups: 一个具名捕获组数组,没有则为 null。
规则
只有正则表达式使用了表示全局检索的 "g" 标志时,该属性才会起作用。此时应用下面的规则:
- 如果 lastIndex 大于字符串的长度,则 regexp.test 和 regexp.exec 将会匹配失败,然后 lastIndex 被设置为 0。
- 如果 lastIndex 等于字符串的长度,且该正则表达式匹配空字符串,则该正则表达式匹配从 lastIndex 开始的字符串。
- 如果 lastIndex 等于字符串的长度,且该正则表达式不匹配空字符串 ,则该正则表达式不匹配字符串,lastIndex 被设置为 0.。
- 否则,lastIndex 被设置为紧随最近一次成功匹配的下一个位置。